Avi Wigderson has this wonderful talk about the power and limitations of randomness in computation, surveying the beautiful area of randomized algorithms, and the surprising connection between pseudorandomness and computational intractability. If you haven’t seen it already, I highly recommend it!
There is a part of the talk when Avi fearlessly engages the age-old question of the meaning of randomness. What does it mean for something to be random? We theoretical computer scientists often speak of “coin tosses”: many of our algorithms toss coins to decide what to do, and Alice and Bob toss coins to foil their mortal enemy Eve. Avi asks, “Is a coin toss random?”
Imagine that I hold in my hand a (fair) coin, and a second after I toss it high in the air, you, as you are watching me, are supposed to guess the outcome when it lands on the floor. What is the probability that you will guess correctly? 50-50 you say? I agree!
(Reproduced from the essay version of his talk). But now, Avi says, imagine that the coin toss was repeated, but this time you had some help: you were equipped with a powerful computing device, and accurate sensors, like an array of high speed video recorders. The coin suddenly starts to look a lot less random now! If your computer and sensors were good enough, you’d likely be able to predict the outcome of the coin toss nearly perfectly. In both cases the coin toss was the same, but the observer changed, and so did the amount of randomness in the situation. Thus, he contends, randomness is in the eye of the beholder.
From here, Avi launches into an excellent discussion of pseudorandomness and other topics. However, I’m going to forge onwards — foolishly, perhaps — with the original theme: what is randomness? As he pointed out, the randomness in the coin toss situation depended on the capabilities of the observer. Thus, one could argue that a coin toss is not truly random, because in principle you could predict the outcome. Is there a situation that is intrinsically random, no matter how powerful or omniscient the observer was? Put another way: is there a process by which I can generate a bit that no external super-being could possibly predict? Can you tell if a bit is random?
Enter the physics
Do you believe that the universe is governed by quantum mechanics? If so, then it seems that the matter is settled: quantum mechanics guarantees the existence of intrinsically random events. For those who know basic quantum, generating a truly random bit is easy: simply prepare a qubit state 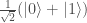
But how do you actually prepare such a qubit, and perform the measurement? If you were a skilled experimentalist with access to perfectly manufactured mirrors and laser sources and detectors, then maybe. But then, how would you know these mirrors and lasers and detectors were built correctly?
For the rest of us down on Earth who don’t have time to learn experimental quantum physics and personally guarantee that all our laboratory equipment was built to specification, we’d like to be able to take some apparatus like a hardware random number generator and test whether its outputs were genuinely random — without having to open up the device and inspect its insides. Can we test randomness in a black box fashion?
It is easy to see that, if you only had input/output access to a black box device, there’s no test you can perform to reliably tell whether the device’s outputs are random. Intuitively, this is because for every test, you can construct a black box device that deterministically produces outputs that pass the test! Here’s a proof-by-Dilbert-cartoon:

What about statistical tests for randomness? Pseudorandom number generators are usually subject to an extensive battery of tests that check for suspicious patterns or regularities. Again, these are not fool-proof: one can design a fixed string that “diagonalizes” against all these heuristics and passes them all!
The power of non-locality
Black-box randomness testing seems like a hopeless task. But it turns out that, with a tiny extra assumption, it becomes possible! The added ingredient is non-locality.
Imagine that we had a hardware random number generator (HRNG) that we wanted to test, and suppose that the HRNG consisted of two separate pieces — call them Piece A and Piece B. Prevent A and B from communicating, either by surrounding them with Faraday cages or putting them on opposite sides of the galaxy. Now play the following game with them: generate a random bits x, y, and give x to A and y to B. Collect output bits a from A and b from B, and check if a + b = x Λ y (where a + b indicates the parity of the two bits). If so, the devices win this curious little game.
Suppose A and B were completely deterministic devices: their outputs a and b were fixed deterministic functions of their inputs x and y, respectively. Then it is not hard to see that, over the random choices of x and y, they can only win this game with probability 3/4.
What if you somehow knew that the devices were winning with probability greater than 3/4? What must you conclude? These devices — and hence their output bits — must be acting randomly. The killer fact is, it’s actually possible to win this game with probability strictly greater than 3/4! This can happen if part A and part B, though isolated, utilize something called quantum entanglement — a phenomenon that Einstein derisively termed “spooky action at a distance”.
We’ve made some headway on randomness testing, it seems. First, this game I’ve described does not require you to peer inside the HRNG. Second, if the HRNG wins the game with high enough probability, you’ve certified that its outputs must contain some randomness. Third, quantum mechanics says it is possible to build a HRNG to win the game. Finally, as a bonus: you don’t need to believe in quantum mechanics in order to trust the conclusion that “If the devices win with probability greater than 3/4, they must be producing randomness”!
What I’ve described to you is a distillation of the famous Bell’s Theorem from physics, which says that quantum mechanics is inconsistent with any so-called “hidden variable” theory of nature that respects locality (i.e. you can separate systems by distances so they cannot communicate or influence each other). This is why people say that quantum mechanics exhibits “non-local” behavior, because games like the one above can be won with probability greater than 3/4 (which has been demonstrated experimentally). Bell’s Theorem has been historically important in establishing a dividing line between classical and quantum theories of nature; but today we have a new interpretation: one can view Bell’s Theorem — published half a century ago — as saying that we can meaningfully perform randomness testing.
Randomness expansion — to infinity and beyond!
“Wait a minute,” you say. “While you’ve presented a test for randomness, this isn’t so useful — to even run the test you need 2 bits of randomness to generate x and y! Why test a HRNG if you already have randomness to begin with?”
True. A HRNG test isn’t very useful when it requires more randomness than is produced. It’s like the current state of fusion reactors: they produce less energy than is required to run them. But researchers in quantum cryptography realized that you could get a randomness efficient test, using less randomness than the amount that is produced by the HRNG. For example, one can start with 100 random bits, run one of these randomness efficient tests, and end up with, say, 200 random bits, a net gain of 100! In a sense, the amount of randomness you now possess has been expanded — hence these tests are called randomness expansion protocols.
Roger Colbeck, in his Ph.D. thesis from 2006, came up with a protocol that uses m bits of initial seed randomness, and certifies cm bits of output randomness using a HRNG that consists of 3 isolated parts, where c is some constant (approximately 3/2). Later in 2010, Pironio et al. gave a protocol that expands m bits of seed randomness to m2 certified bits. In 2011, two simultaneous works — one by Vazirani and Vidick, and one by Fehr, et al. — demonstrated a protocol that attained exponential expansion: starting with m bits, one can certify that a 2-part HRNG produces a whopping 2m certified bits of randomness!
While perhaps 2100 random bits starting from a mere 100 is probably more than you’d ever need, the tantalizing question still stands: is there a limit to how much randomness you can certify, starting with a finite amount of seed randomness? In the upcoming Quantum Information Processing conference, Matt Coudron and I will show that there is no upper limit, and that infinite randomness expansion is possible. We give a protocol where, starting with say 1000 random bits, you can command a finite number of devices (which is eight in our protocol) to produce an unbounded amount of randomness. Furthermore, this protocol is immune to any secret backdoors installed in your HRNG (e.g. by a certain security agency) — the output of your HRNG is guaranteed to be secure against any external eavesdropper.
Classical control of quantum systems
Let’s take a step back from this frenetic expansion of randomness, and appreciate the remarkable nature of these protocols. Note that, this entire time, we know almost nothing about the HRNG being tested. It could have been specially designed by some malicious adversary to try to fool your test as much as possible. It could have at its disposal enormous computational power, like access to the Halting Problem oracle. It could even use quantum entanglement in some yet-unimagined way to try to defeat your test. Yet, by isolating parts of the HRNG from each other, and employing a simple check on their input and outputs, a limited classical being can force the HRNG to produce a long stream of random bits.
In a time when random number generators can be stealthily compromised by altering the dopants in a microchip, or by the intentional weakening of cryptographic standards by government agencies, the ability to rigorously and soundly test randomness has outgrown its philosophical origins in the nature of physical law, and become something of operational significance.
To return to our original question, though: can we tell if a bit is random? We can, but only by employing some some of the deepest ideas drawn from theoretical computer science and quantum physics. More broadly, this paradigm of classically controlling untrusted quantum devices has given rise to what’s called device independent quantum information processing. Not only can we classically manipulate quantum devices to produce genuine randomness, we can do a whole lot more: today we know how to securely exchange secret keys and even perform general quantum computations in a device independent manner! The scope and potential of device independent QIP is enormous, and I think we’ve only gotten started.

Interesting! Yet, it seems that your (randomized) randomness test doesn’t answer exactly the original question: it will tell you that the bit (the HRNG) has some randomness, but not that it meet some randomness specification (i.e., produces an output according to the distribution it claims to) — does it?
And if to do so you want to apply some property testing to the output, what about the robustness of the said tests to the random input themselves? That is, if I have, say, already some (limited) randomness, and want to use it to test the distribution of some HNRG — how much must I trust the original randomness? I may be wrong, but it seems to me that most randomized algorithms, property testers included, assume their internal coins to be uniform; how robust to that assumption can they be made?
And what about your randomness expansion — if I have 100 independent random bits with unknown bias $p$, how will the output of the randomness expander be distributed (as a function of this unknown $p$)?
Clement, randomness expansion protocols generally guarantee that the output is not only random, but is actually very close to uniform. This is because the protocol first guarantees that the output contains high min-entropy, and then runs a randomness extractor (using a small amount of additional uniform seed) to “clean it up” to produce near-uniform randomness.
As far as the assumption about the initial seed, usually we assume it is uniform and independent. The case when it is not uniform has only been recently studied, in a closely related subject called “randomness amplification”. Recently, works by Colbeck/Renner and Brandao, et al. have demonstrated that one can, in a device independent manner, certify near-uniform randomness using a seed that comes from a so-called “Santha-Vazirani source”, where the bits are guaranteed to have *some* independence from another. In my paper with Matt, we combine their results with our infinite randomness expansion protocol to get a “infinite randomness amplification” protocol. In other words, starting from say 1000 bits of imperfect randomness, one can certify an unbounded amount of near uniform randomness.
Finally, as a technical note, the closeness to uniform depends on the length of the initial seed. Our infinite randomness expansion protocol guarantees that the output is exp(-m)-close to uniform, if you start with an m bit seed.
OK — thanks!